
네이버나 구글에서 수동으로 페이지(url)수집요청하기 자주하면 좋을까? || SEO(검색엔진최적화)
네이버 웹마스터도구나 구글 서치콘솔을 보면 url수집요청기능이 있습니다.
그런데 블로거분들이 이 기능을 활용하면서 새로운 글을 업로드할 때마다 수동으로 수집요청을 하거나 또는 색인이 안된 글의 url들을 이 기능으로 다시 수집요청을 반복하는 사례들을 종종 목격하게 됩니다.
과연 이 기능을 이용해서 수집요청을 자주하면 좋을까?
결론은 페이지수집요청을 자주하면 절대로 좋지 않고 경우에 따라 네이버에서는 스팸사이트로 낙인찍힐 우려까지 있습니다.
페이지수집요청관련한 정보는 구글보다 오히려 네이버에 보다 많이 공개되어 있는데요.
서치어드바이저에는 다음과 같은 문구가 보입니다.
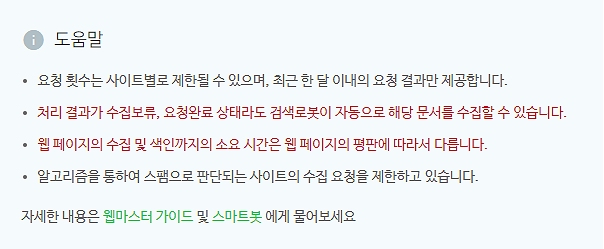
이 정도만으로도 수집요청을 남용하지 말라는 의미로 해석될 수 있을텐데요.
https://searchadvisor.naver.com/guide/request-crawl
수집요청 및 검색제외
웹페이지 수집 정책 웹마스터도구에서 제공하는 웹 페이지 수집요청은 검색로봇이 미처 방문하지 못한 사이트의 주요 웹페이지를 사용자가 직접 수집요청을 하는 기능으로서, 사이트 별로 제
searchadvisor.naver.com
이 글을 보면 보다 명확해집니다.
https://blog.naver.com/naver_webmaster/221320610480
최근 발생했던 수집요청실패에 대해 말씀드립니다
안녕하세요 웹마스터도구 팀입니다. 최근 웹마스터도구에서 웹 페이지 수집요청시 처리 결과가 지연 또는 ...
blog.naver.com
여기에서는 수집요청을 악용한 사례를 언급하면서 보다 구체적인 정보를 제공해주고 있습니다.
그렇다면 Google은 어떨까요?
구글에서도 서치콘솔에서 url검사 후 색인요청을 할 수 있습니다.
그런데 구글에서도 이 기능관련해서 자세히 언급은 하지 않고 있지만 역시 수집요청의 남용을 경계하고 있습니다.
참조;
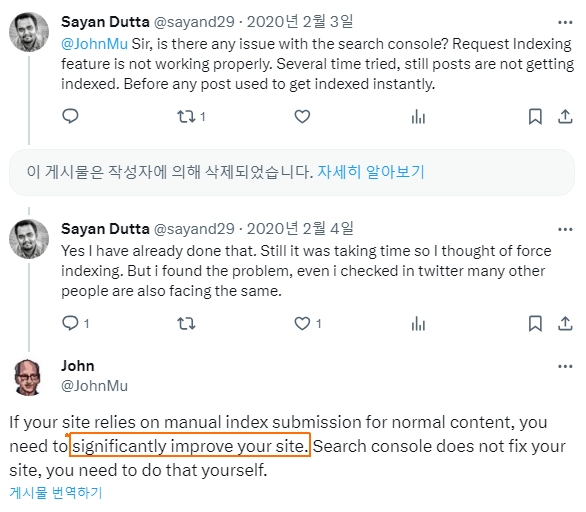
또한 구글 개발자문서에는 "동일한 URL에 재크롤링을 여러 번 요청하더라도 더 빨리 크롤링되지는 않습니다."라는 문구도 있습니다.
즉, 수동 페이지 수집요청은 아무 의미없이 하는 것이 아니고 해당 페이지가 상당한 수준으로 업테이트되었을 때 이용하여야한다는 의미입니다.
바람직한 방향으로는 서치콘솔에서 곧바로 url검사 > 페이지수집요청을 할 것이 아니라
아래 페이지 > 페이지 색인이 생성되지 않는 이유 항목을 먼저 점검해서 필요에 의해서만 수집요청을 하는 것입니다.
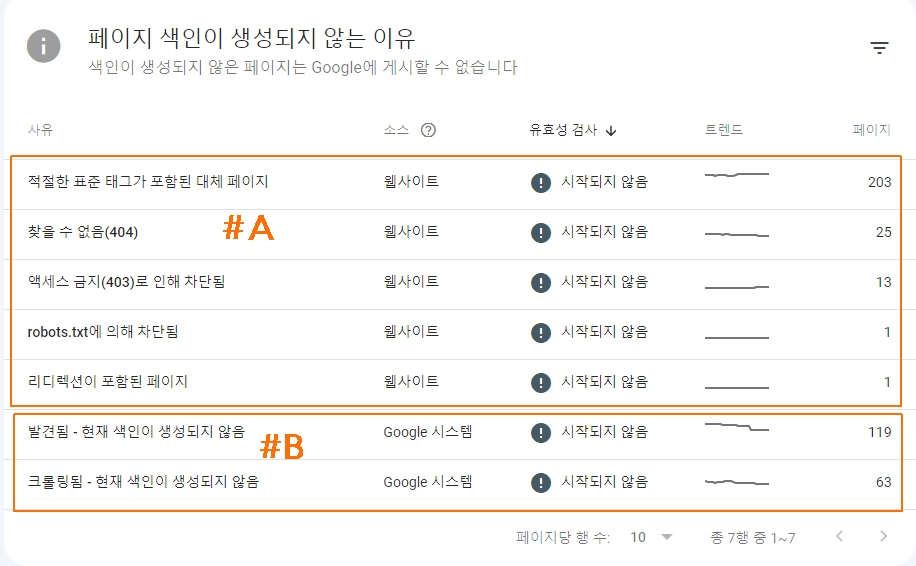
이 그림에서 #A 사유 중에서 변경/개선이 합당하다면 사이트내에서 작업 후 url을 재검사한 후 수집요청을 할 수 있습니다.
#B에서 "발견됨 - 현재 색인이 생성되지 않음"의 경우 아직 크롤링하지 않았으므로 좀 더 기다리는 것이 바람직하며 "크롤링 됨 - 현재 색인이 생성되지 않음"의 경우 곧바로 수집요청을 할 필요가 없지만 일부 url이 콘텐츠품질이나 중복문서 이슈 등이 있다고 판단하여서 이를 페이지내에서 문제를 해소한 이후에는 페이지를 제출할 수 있습니다.
참조:
https://support.google.com/webmasters/answer/7440203
페이지 색인 생성 보고서 - Search Console 고객센터
도움이 되었나요? 어떻게 하면 개선할 수 있을까요? 예아니요
support.google.com
아울러 최근 이슈로 파비콘관련 업데이트로 인해 검색결과에서 업데이트된 파비콘노출이 원하는대로 안되는 경우가 있습니다.
이 때에는 사이트내에서 업데이트된 파비콘이미지의 url에 대해 url검사 후 수집요청을 할 수 있습니다.
이쯤해서 Crawl Budget을 언급하지 않을 수 없는데요.
이에 대한 자세한 정보는 https://developers.google.com/search/blog/2017/01/what-crawl-budget-means-for-googlebot?hl=ko
Googlebot 크롤링 예산의 의미 | Google 검색 센터 블로그 | Google for Developers
developers.google.com
에서 확인할 수 있습니다.
결국 구글은 해당 사이트에 대해 소정의 Crawl Budget에 의해 크롤링/인덱싱하고 잇으므로 페이지수집요청을 자주할 필요도 없고 또한 위에서 언급한 미색인사유들을 해소할 필요도 없고 xml사이트맵이나 rss등을 제출한 상태라면 조급하게 이 기능을 굳이 사용할 필요도 없습니다.
추가) 연관 글입니다.
https://hiseosem.tistory.com/entry/구글-서치콘솔에서의-페이지-색인-데이터-이해하기
'SEO(검색엔진최적화)' 카테고리의 다른 글
| Google 웹 검색을 위한 2024년 3월 스팸 업데이트 소식(아주 중요!) (0) | 2024.03.17 |
|---|---|
| 구글 서치콘솔에서의 페이지 색인 데이터 이해하기 (7) | 2024.02.12 |
| 위험한 백링크(인바운드링크)들 없이 정상적인 SEO를 수행한 결과 (2) | 2024.02.04 |
| 구글검색결과에서 저장된 페이지(캐시된 페이지)확인하는 방법 (6) | 2024.01.26 |
| 워드프레스 블로그 SEO를 잘 하려면(7가지 방향) (11) | 2024.01.13 |




댓글